自作のWebアプリ、 ザ・地域統計パワーバトル が、LODチャレンジ2018において、グランプリにあたる最優秀賞をいただきました。また、併せて日立株式会社様より Inspire the LOD賞を頂きました。
さらに、自作のオントロジー、OWL de ラーメンオントロジー は、オントロノミー合同会社様から オントロジー賞を頂きました。
自作アプリ等の公表の場を与えてくださるだけでも本当にありがたいことで、それに加えて賞までいただけるのは感謝しきれないくらいです。関係者様ありがとうございます。
僕がデータの利活用やプログラミングに取り組み始めたのは3年ほど前で、それ以前はさほど興味を持っていませんでした。
以前は、休日は大好きな魚釣りに行くことが多かったのですが、一日家を空けて魚を釣って楽しんで帰ってくると、家族から白い目で見られることが多く、やむ無く封印することになりました。
冬はスノーボードに行くのを楽しみにしていましたが、行くたびに時間とお金と体力を使い果たしすぎるために、これもやむ無く封印しています。
そこで目を付けたのがオープンデータ利活用です。
1.家にいながらスキマ時間でできるので家族サービスの支障にならない。
2.PCひとつでできるのでお金がかからず、家計にやさしい。
3.社会貢献にもなる。
4.お父さん意外とすごい人だったんだ、って娘に褒められる。
長く続けていけたらなぁ、と思っています。
2018年11月11日日曜日
2018年9月11日火曜日
IMIツール Ver 1.0.0
共通語彙を利活用するためのツールである IMIツール は、先日まで検証版だったが、このたび待望の正式版 Ver 1.0.0 がリリースされた。
さっそく使ってみる。
とりあえず、検証版で作ったDMDを読み込ませる。
む、エラーだ (-_-)
まあ、仕様が変わったのだろう。しようがない…。
オヤジギャグはさておき、気を取り直して、一からDMDを作り直す。
手持ちのエクセル表を読み込ませて、適切なクラス・プロパティをブラウザ上で選んでいく。
応用語彙を、IMI語彙記法を用いて追加する。
この辺りの操作感は検証版と同じだ。
さて、DMDが無事完成し、RDF出力だ。
果たして検証版のダメな点は直っているのだろうか。
1 JSON-LD ⇒ 検証版から据え置き。不具合解消なし。
2 RDF-XML ⇒ 検証版から据え置き。不具合解消なし。
3 Turtle ⇒ 検証版から据え置き。不具合解消なし。
4 主語の扱い ⇒ 検証版から据え置き。不具合解消なし。
…ぶっちゃけこれでは使い物にならないっす。
技術委員さん、このRDFちゃんとチェックしてます?ほんとにいいのこれで??
経産省やIPAは、共通語彙基盤を本気で流行らせたい気が無いのだろうか… (-_-)
1千万くれたら僕が最高のツールを作ります。
(ウソです)
さっそく使ってみる。
とりあえず、検証版で作ったDMDを読み込ませる。
む、エラーだ (-_-)
まあ、仕様が変わったのだろう。しようがない…。
オヤジギャグはさておき、気を取り直して、一からDMDを作り直す。
手持ちのエクセル表を読み込ませて、適切なクラス・プロパティをブラウザ上で選んでいく。
応用語彙を、IMI語彙記法を用いて追加する。
この辺りの操作感は検証版と同じだ。
さて、DMDが無事完成し、RDF出力だ。
果たして検証版のダメな点は直っているのだろうか。
1 JSON-LD ⇒ 検証版から据え置き。不具合解消なし。
2 RDF-XML ⇒ 検証版から据え置き。不具合解消なし。
3 Turtle ⇒ 検証版から据え置き。不具合解消なし。
4 主語の扱い ⇒ 検証版から据え置き。不具合解消なし。
…ぶっちゃけこれでは使い物にならないっす。
技術委員さん、このRDFちゃんとチェックしてます?ほんとにいいのこれで??
経産省やIPAは、共通語彙基盤を本気で流行らせたい気が無いのだろうか… (-_-)
1千万くれたら僕が最高のツールを作ります。
(ウソです)
2018年8月11日土曜日
統計LODのSPARQLクエリ解説(小地域編)
このたび、Webアプリ 「ザ・地域統計パワーバトル」 を公開した。
このアプリは「シビックパワーバトル」に着想を得て開発したものだ。
バトル自体は興味を引くためのジョークだが、地域と地域を比較したり、また日本(全国値)と比較することで、自分の住んでいる地域の特徴を知り、どのような問題点を持つか把握することが可能となる。地域分析ツールという観点で遊んでいただけたら幸いだ。
さて、このアプリは、e-StatのWeb APIからデータを取得し表示させている。
都道府県と市区町村のデータは REST API から、町丁・字の「小地域」のデータは、統計LOD のSPARQL APIから取得している。
都道府県と市区町村のデータは、SPARQL APIからも取得することが可能だが、実行速度のより高速なREST APIを利用している。
小地域データは現在、SPARQL APIからのみの提供だ。
本稿では、統計LODの小地域データを扱うためのSPARQLクエリを紹介する。クエリをコピペして、統計LODのエンドポイントでお試しあれ。
1 平成27年国勢調査の対象自治体の一覧
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX sacs: <http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic: <http://imi.go.jp/ns/core/rdf#>
select distinct ?code ?pref ?area
where {
?s sdmx-dimension:refArea ?code ;
qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200521/d0003148521>.
?code sacs:prefectureLabel ?pref ;
ic:表記 ?area ;
}order by ?code
このクエリで、平成27年国勢調査の対象自治体の「期間付き標準地域コード」を取得することができる。(重いので乱発しないこと!)
2 京都市左京区に含まれる小地域の一覧
PREFIX smallArea: <http://data.e-stat.go.jp/lod/terms/smallArea/>
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX sac: <http://data.e-stat.go.jp/lod/sac/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select *
where {
?s a smallArea:SmallAreaCode ;
dcterms:isPartOf sac:C26103-19700401 ;
rdfs:label ?name .
} order by ?s
上記の sac:C26103-19700401 は平成27年国勢調査時点の、京都市左京区の期間付き標準地域コードである。この部分を変えることで他の市区町村の情報を得ることができる。
3 京都市左京区聖護院山王町の情報
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
select *
where {
sa-g00200521-2015:S26103018006 ?p ?o .
}
4 京都市左京区聖護院山王町のポリゴン
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
PREFIX geo: <http://www.opengis.net/ont/geosparql#>
select ?polygon
where {
sa-g00200521-2015:S26103018006 geo:hasGeometry [ geo:asWKT ?polygon ] .
}
小地域のポリゴンを取得することもできる。当アプリではこのクエリは使っていないが、オープンストリートマップなどで領域を表示させるのも面白いと思う。
5 京都市左京区聖護院山王町の年齢別・男女別人口
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX estat-measure: <http://data.e-stat.go.jp/lod/ontology/measure/>
select ?age ?sex ?population
where {
?s sdmx-dimension:refArea sa-g00200521-2015:S26103018006 ;
qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200521/ds012015003>;
cd-dimension:age ?age;
cd-dimension:sex ?sex;
estat-measure:population ?population.
}order by ?sex ?age
このクエリで、いわゆる「人口ピラミッド」に必要な情報を得ることができる。
6 京都市左京区聖護院山王町の年齢別・男女別人口、外国人人口、世帯数、配偶関係、労働力状態
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX estat-measure: <http://data.e-stat.go.jp/lod/ontology/measure/>
PREFIX g00200521-dimension-2015: <http://data.e-stat.go.jp/lod/ontology/g00200521/dimension/2015/>
PREFIX g00200521-dimension-2010: <http://data.e-stat.go.jp/lod/ontology/g00200521/dimension/2010/>
select ?dataset ?sex ?age ?maritalStatus ?labourForce ?population ?households ?avrage
where {
?s sdmx-dimension:refArea sa-g00200521-2015:S26103018006 ;
qb:dataSet ?dataset .
OPTIONAL{
?s cd-dimension:age ?age;
cd-dimension:sex ?sex;
estat-measure:population ?population.
}
OPTIONAL{
?s estat-measure:households ?households .
}
OPTIONAL{
?s cd-dimension:sex ?sex;
estat-measure:population ?population.
}
OPTIONAL{
?s cd-dimension:sex ?sex;
estat-measure:age ?avrage.
}
OPTIONAL{
?s cd-dimension:sex ?sex;
g00200521-dimension-2015:maritalStatus ?maritalStatus;
estat-measure:population ?population.
}
OPTIONAL{
?s cd-dimension:sex ?sex;
g00200521-dimension-2010:labourForce ?labourForce;
estat-measure:population ?population.
}
}order by ?dataset ?sex ?age ?maritalStatus ?labourForce
「ザ・地域統計パワーバトル」では、実際にこのクエリを使ってデータを取得している。
OPTIONAL句で各種データを並列させているところがポイント。
短いクエリを連発するのが良いのか、このような重いクエリにするのが良いのか悩んだが、プログラムが複雑化するのを避けるために、今回は重いクエリ一発で、情報を一気に取得する方法を採用した。
統計LODの実行速度が倍くらいになってくれたらなぁ…。
統計局さん、統計センターさん、日立さん、よろしくお願いします。
おかげさまで快適になりました。
関係者のみなさま、ありがとうございます!!!
このアプリは「シビックパワーバトル」に着想を得て開発したものだ。
バトル自体は興味を引くためのジョークだが、地域と地域を比較したり、また日本(全国値)と比較することで、自分の住んでいる地域の特徴を知り、どのような問題点を持つか把握することが可能となる。地域分析ツールという観点で遊んでいただけたら幸いだ。
さて、このアプリは、e-StatのWeb APIからデータを取得し表示させている。
都道府県と市区町村のデータは REST API から、町丁・字の「小地域」のデータは、統計LOD のSPARQL APIから取得している。
都道府県と市区町村のデータは、SPARQL APIからも取得することが可能だが、実行速度のより高速なREST APIを利用している。
小地域データは現在、SPARQL APIからのみの提供だ。
本稿では、統計LODの小地域データを扱うためのSPARQLクエリを紹介する。クエリをコピペして、統計LODのエンドポイントでお試しあれ。
1 平成27年国勢調査の対象自治体の一覧
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX sacs: <http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic: <http://imi.go.jp/ns/core/rdf#>
select distinct ?code ?pref ?area
where {
?s sdmx-dimension:refArea ?code ;
qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200521/d0003148521>.
?code sacs:prefectureLabel ?pref ;
ic:表記 ?area ;
}order by ?code
このクエリで、平成27年国勢調査の対象自治体の「期間付き標準地域コード」を取得することができる。(重いので乱発しないこと!)
2 京都市左京区に含まれる小地域の一覧
PREFIX smallArea: <http://data.e-stat.go.jp/lod/terms/smallArea/>
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX sac: <http://data.e-stat.go.jp/lod/sac/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select *
where {
?s a smallArea:SmallAreaCode ;
dcterms:isPartOf sac:C26103-19700401 ;
rdfs:label ?name .
} order by ?s
上記の sac:C26103-19700401 は平成27年国勢調査時点の、京都市左京区の期間付き標準地域コードである。この部分を変えることで他の市区町村の情報を得ることができる。
3 京都市左京区聖護院山王町の情報
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
select *
where {
sa-g00200521-2015:S26103018006 ?p ?o .
}
4 京都市左京区聖護院山王町のポリゴン
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
PREFIX geo: <http://www.opengis.net/ont/geosparql#>
select ?polygon
where {
sa-g00200521-2015:S26103018006 geo:hasGeometry [ geo:asWKT ?polygon ] .
}
小地域のポリゴンを取得することもできる。当アプリではこのクエリは使っていないが、オープンストリートマップなどで領域を表示させるのも面白いと思う。
5 京都市左京区聖護院山王町の年齢別・男女別人口
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX estat-measure: <http://data.e-stat.go.jp/lod/ontology/measure/>
select ?age ?sex ?population
where {
?s sdmx-dimension:refArea sa-g00200521-2015:S26103018006 ;
qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200521/ds012015003>;
cd-dimension:age ?age;
cd-dimension:sex ?sex;
estat-measure:population ?population.
}order by ?sex ?age
このクエリで、いわゆる「人口ピラミッド」に必要な情報を得ることができる。
6 京都市左京区聖護院山王町の年齢別・男女別人口、外国人人口、世帯数、配偶関係、労働力状態
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sa-g00200521-2015: <http://data.e-stat.go.jp/lod/smallArea/g00200521/2015/>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX estat-measure: <http://data.e-stat.go.jp/lod/ontology/measure/>
PREFIX g00200521-dimension-2015: <http://data.e-stat.go.jp/lod/ontology/g00200521/dimension/2015/>
PREFIX g00200521-dimension-2010: <http://data.e-stat.go.jp/lod/ontology/g00200521/dimension/2010/>
select ?dataset ?sex ?age ?maritalStatus ?labourForce ?population ?households ?avrage
where {
?s sdmx-dimension:refArea sa-g00200521-2015:S26103018006 ;
qb:dataSet ?dataset .
OPTIONAL{
?s cd-dimension:age ?age;
cd-dimension:sex ?sex;
estat-measure:population ?population.
}
OPTIONAL{
?s estat-measure:households ?households .
}
OPTIONAL{
?s cd-dimension:sex ?sex;
estat-measure:population ?population.
}
OPTIONAL{
?s cd-dimension:sex ?sex;
estat-measure:age ?avrage.
}
OPTIONAL{
?s cd-dimension:sex ?sex;
g00200521-dimension-2015:maritalStatus ?maritalStatus;
estat-measure:population ?population.
}
OPTIONAL{
?s cd-dimension:sex ?sex;
g00200521-dimension-2010:labourForce ?labourForce;
estat-measure:population ?population.
}
}order by ?dataset ?sex ?age ?maritalStatus ?labourForce
「ザ・地域統計パワーバトル」では、実際にこのクエリを使ってデータを取得している。
OPTIONAL句で各種データを並列させているところがポイント。
短いクエリを連発するのが良いのか、このような重いクエリにするのが良いのか悩んだが、プログラムが複雑化するのを避けるために、今回は重いクエリ一発で、情報を一気に取得する方法を採用した。
おかげさまで快適になりました。
関係者のみなさま、ありがとうございます!!!
2018年6月25日月曜日
(各論)IMIツールの「データ形式変換」機能について
作成したDMDを、元データ(エクセル表など)と一緒に、IMIツール「データ形式変換」に読み込ませると、簡単に共通語彙対応データ(JSON-LD、RDF/XML、Turtle)が出力できる。
ここでは、データ形式変換 から出力された各データについて、私見を紹介する。
1 JSON-LD形式 ⇒ (^^)
(例)共通語彙基盤「妖精」(JSON-LD形式)
データの階層構造もきれいに収まっており、視認性もよくGOOD!
一点疑問に思うのは、URIを示す表現が以下のようになっていること。
"ic:参照先": {
"@value": "http://example.com/xxx/aaa.html",
"@type": "xsd:anyURI"
}
JSON-LDでは、次のように、目的語がURIの場合は @id を使うのが一般的な記法だと思う。
"ic:参照先": {
"@id": "http://example.com/xxx/aaa.html"
}
2 RDF/XML形式 ⇒ (-_-)
(例)共通語彙基盤「妖精」(RDF/XML形式)
JSON-LD同様、データの階層構造はきれいに収まっているが、出力されるテキストに、改行コードやインデントスペースが全く入っていないのがつらすぎる。
ブラウザに読み込ませたら構造が分かるが、そのままの状態ではテキストエディターでの編集は困難。
また、JSON-LD同様、URIを示す表現に疑問符。
<ic:画像 rdf:datatype="xsd:anyURI">http://example.com/xxx.jpg</ic:画像>
rdf:resource を使って以下のように記述するのが一般的。
<ic:画像 rdf:resource="http://example.com/xxx.jpg"/>
3 Turtle形式 ⇒ (-"-)
(例)共通語彙基盤「妖精」(Turtle形式)
ブランクノード表現が多用されており読みにくい。
形式的には一応Turtleの要件を満たしているが、これではN-Triplesとほとんど一緒。
Turtleの優れているところは人間が読みやすい点。これではダメだ。
また、冒頭で名前空間接頭辞の宣言をしているにも関わらず、データ内で接頭辞を使っていないところもダメダメな感じ。
あと、上述の2形式と同様、URIの扱いに疑問符。
"http://example.com/xxx/aaa.html"^^xsd:anyURI
スタンダードなのはこちら。
<http://example.com/xxx/aaa.html>
ちなみに私はRDFタートルズの一員である。
個人的な思いとしても、もっとTurtle生成プログラムを作りこんでいただきたいところだ。最低でもこのくらいにはしてほしいなぁ。
4 主語の扱い
すべての出力データに関して、共通の問題点は 主語(subject) がないところ。
RDFはご存じのとおり主語・述語・目的語のトリプル構造となっており、文法的には、主語には URI 又は ブランクノード を使うこととされている。
「中間ノード」の主語に対し、ブランクノードを利用するのは何ら問題ない。
一方で、ある事物を示す「おおもとの主語」に対しては、ブランクノードではなくURIを付与するのが普通だ。
しかしながら、IMIツールから出力されるRDFは、おおもとの主語もブランクノードになってしまっている。
おおもとの主語にURIが設定されていないと、RDFとしては扱いづらく、トリプルストアに入れ込んだときも扱いが困難となる。
私は、何とかして主語を設定しようと、IMIツールの設定項目をいろいろ試したり、IMI語彙記法でいろいろと書き込んでみたが、上手くいかなかった。
(他に方法があるのかもしれないが…)
IPAさんにお願いしたいのは、IMIツールのGUI上に、主語の名前空間URIの設定項目を作り、そこに入力したURIに、データ内のいずれかの列のデータをくっつけたものを、主語URIとして出力できるようにすること。
5 まとめ
目につく不具合はいくつかあるものの、一旦DMDを作ってしまえば、様々な形式のRDFが簡単に出力できるのは非常に便利。
上記で挙げた不具合をすべて解消し、(^^♪ になった 正式版IMIツール の早期リリースを望みます。よろしくお願いします m(__)m
ここでは、データ形式変換 から出力された各データについて、私見を紹介する。
1 JSON-LD形式 ⇒ (^^)
(例)共通語彙基盤「妖精」(JSON-LD形式)
データの階層構造もきれいに収まっており、視認性もよくGOOD!
一点疑問に思うのは、URIを示す表現が以下のようになっていること。
"ic:参照先": {
"@value": "http://example.com/xxx/aaa.html",
"@type": "xsd:anyURI"
}
JSON-LDでは、次のように、目的語がURIの場合は @id を使うのが一般的な記法だと思う。
"ic:参照先": {
"@id": "http://example.com/xxx/aaa.html"
}
2 RDF/XML形式 ⇒ (-_-)
(例)共通語彙基盤「妖精」(RDF/XML形式)
JSON-LD同様、データの階層構造はきれいに収まっているが、出力されるテキストに、改行コードやインデントスペースが全く入っていないのがつらすぎる。
ブラウザに読み込ませたら構造が分かるが、そのままの状態ではテキストエディターでの編集は困難。
また、JSON-LD同様、URIを示す表現に疑問符。
<ic:画像 rdf:datatype="xsd:anyURI">http://example.com/xxx.jpg</ic:画像>
rdf:resource を使って以下のように記述するのが一般的。
<ic:画像 rdf:resource="http://example.com/xxx.jpg"/>
3 Turtle形式 ⇒ (-"-)
(例)共通語彙基盤「妖精」(Turtle形式)
ブランクノード表現が多用されており読みにくい。
形式的には一応Turtleの要件を満たしているが、これではN-Triplesとほとんど一緒。
Turtleの優れているところは人間が読みやすい点。これではダメだ。
また、冒頭で名前空間接頭辞の宣言をしているにも関わらず、データ内で接頭辞を使っていないところもダメダメな感じ。
あと、上述の2形式と同様、URIの扱いに疑問符。
"http://example.com/xxx/aaa.html"^^xsd:anyURI
スタンダードなのはこちら。
<http://example.com/xxx/aaa.html>
ちなみに私はRDFタートルズの一員である。
個人的な思いとしても、もっとTurtle生成プログラムを作りこんでいただきたいところだ。最低でもこのくらいにはしてほしいなぁ。
4 主語の扱い
すべての出力データに関して、共通の問題点は 主語(subject) がないところ。
RDFはご存じのとおり主語・述語・目的語のトリプル構造となっており、文法的には、主語には URI 又は ブランクノード を使うこととされている。
「中間ノード」の主語に対し、ブランクノードを利用するのは何ら問題ない。
一方で、ある事物を示す「おおもとの主語」に対しては、ブランクノードではなくURIを付与するのが普通だ。
しかしながら、IMIツールから出力されるRDFは、おおもとの主語もブランクノードになってしまっている。
おおもとの主語にURIが設定されていないと、RDFとしては扱いづらく、トリプルストアに入れ込んだときも扱いが困難となる。
私は、何とかして主語を設定しようと、IMIツールの設定項目をいろいろ試したり、IMI語彙記法でいろいろと書き込んでみたが、上手くいかなかった。
(他に方法があるのかもしれないが…)
IPAさんにお願いしたいのは、IMIツールのGUI上に、主語の名前空間URIの設定項目を作り、そこに入力したURIに、データ内のいずれかの列のデータをくっつけたものを、主語URIとして出力できるようにすること。
5 まとめ
目につく不具合はいくつかあるものの、一旦DMDを作ってしまえば、様々な形式のRDFが簡単に出力できるのは非常に便利。
上記で挙げた不具合をすべて解消し、(^^♪ になった 正式版IMIツール の早期リリースを望みます。よろしくお願いします m(__)m
(各論)IMIツールの「DMD作成支援」機能について
共通語彙対応データを作るには、まず DMD(Data Model Description / データモデル記述)を作る必要がある。
DMDは、特定のデータを共通語彙対応にするための「設計図」のようなもの。
一旦DMDを作ってしまえば、元データ(エクセル表など)と一緒に、IMIツール に読み込ませるだけで、簡単に共通語彙対応のRDFデータ(JSON-LD、RDF/XML、Turtle)ができる、という仕組みだ。
良い点は、IMIツールを使えば、ほぼマウス操作のみで割と簡単にDMDが作れるところ。
また、一旦DMDを作ってしまえば、何度でも使い回しができ、そのDMDを配布すれば誰でも同じように使えるところ。優れたDMDを作れば、それが全国津々浦々に広まる可能性を秘めている。
悪い点は、構造化項目明記法により、データ構造が非常に複雑になるため、IMIツール以外の方法(手作業など)で作るのが現実的でないところ。
さて、ここで、IMIツールの DMD作成支援 を実際にに使ってみて感じた点を、以下に紹介させていただく。
良いと感じたところは、GUIがなかなか良くできていて、クラス(型)やプロパティの設定を、マウス操作のみで直観的に行うことができるところだ。
一方、難しいと思った点は 応用語彙 の追加だ。
「徳川将軍一覧」のデータを例にあげると、将軍は「人」なので、ルートとなるクラスは ic:人型 にする、と、誰しも考えるところだろう。
そして、コア語彙だけでは表現できない、徳川将軍固有の項目については、応用語彙として追加したい、と考える。
そこで私は、ルートである ic:人型クラスに、応用語彙のプロパティを追加しようと頑張ったのだが、どうしてもできない。
しばらく悩んで理解したのは、コア語彙クラスには、そのクラスが持つコア語彙プロパティしかセットできない、ということ。
言い換えると、応用語彙のプロパティを追加したい場合は、ic:人型クラスを継承した独自定義のクラスを作って、そいつをルートクラスとしなければならない、ということだ。
理解すれば簡単なことだが、理解するまでかなり悩んだので、もうちょっと分かりやすくしてほしい点の一つとして挙げておく。
新しいクラスを作ったり、応用語彙を追加するには、IMI語彙記法 を用いて、その内容を記述する必要がある。その記載例は次の通り。
# 人型クラスを継承した「将軍型クラス」を新規作成する
class ex:将軍型 {@ic:人型};
# 「官位」を示すプロパティを作る
property ex:官位 {@xsd:string} ;
# 将軍型クラスのプロパティとして「官位」を設定する。
set ex:将軍型 > ex:官位;
それほど難しくはないのだが、IMIの固有の記法であるため、やはりある程度の勉強や試行錯誤が必要となる。
これもGUIでできるようになるのが理想的だが、どうしてもできなければ、記載例をもっと豊富に提示していただきたいところだ。
「DMD作成支援」では、応用語彙の追加が最も難しい。
さらに使いやすくなるよう、正式版リリース時にはぜひ改善していただきたい。
DMDは、特定のデータを共通語彙対応にするための「設計図」のようなもの。
一旦DMDを作ってしまえば、元データ(エクセル表など)と一緒に、IMIツール に読み込ませるだけで、簡単に共通語彙対応のRDFデータ(JSON-LD、RDF/XML、Turtle)ができる、という仕組みだ。
良い点は、IMIツールを使えば、ほぼマウス操作のみで割と簡単にDMDが作れるところ。
また、一旦DMDを作ってしまえば、何度でも使い回しができ、そのDMDを配布すれば誰でも同じように使えるところ。優れたDMDを作れば、それが全国津々浦々に広まる可能性を秘めている。
悪い点は、構造化項目明記法により、データ構造が非常に複雑になるため、IMIツール以外の方法(手作業など)で作るのが現実的でないところ。
さて、ここで、IMIツールの DMD作成支援 を実際にに使ってみて感じた点を、以下に紹介させていただく。
良いと感じたところは、GUIがなかなか良くできていて、クラス(型)やプロパティの設定を、マウス操作のみで直観的に行うことができるところだ。
一方、難しいと思った点は 応用語彙 の追加だ。
「徳川将軍一覧」のデータを例にあげると、将軍は「人」なので、ルートとなるクラスは ic:人型 にする、と、誰しも考えるところだろう。
そして、コア語彙だけでは表現できない、徳川将軍固有の項目については、応用語彙として追加したい、と考える。
そこで私は、ルートである ic:人型クラスに、応用語彙のプロパティを追加しようと頑張ったのだが、どうしてもできない。
しばらく悩んで理解したのは、コア語彙クラスには、そのクラスが持つコア語彙プロパティしかセットできない、ということ。
言い換えると、応用語彙のプロパティを追加したい場合は、ic:人型クラスを継承した独自定義のクラスを作って、そいつをルートクラスとしなければならない、ということだ。
理解すれば簡単なことだが、理解するまでかなり悩んだので、もうちょっと分かりやすくしてほしい点の一つとして挙げておく。
新しいクラスを作ったり、応用語彙を追加するには、IMI語彙記法 を用いて、その内容を記述する必要がある。その記載例は次の通り。
# 人型クラスを継承した「将軍型クラス」を新規作成する
class ex:将軍型 {@ic:人型};
# 「官位」を示すプロパティを作る
property ex:官位 {@xsd:string} ;
# 将軍型クラスのプロパティとして「官位」を設定する。
set ex:将軍型 > ex:官位;
それほど難しくはないのだが、IMIの固有の記法であるため、やはりある程度の勉強や試行錯誤が必要となる。
これもGUIでできるようになるのが理想的だが、どうしてもできなければ、記載例をもっと豊富に提示していただきたいところだ。
「DMD作成支援」では、応用語彙の追加が最も難しい。
さらに使いやすくなるよう、正式版リリース時にはぜひ改善していただきたい。
2018年6月24日日曜日
(総論)共通語彙基盤の活用に関する考察
共通語彙基盤の活用を検討する際、誰しもまず悩むのは、「手持ちの表形式のデータを、どのように共通語彙基盤対応とするか」、という点に尽きるのではないだろうか。
例えば、次のような表形式のデータがあるとする。
上記の表データを、汎用性を考慮せず、単純にRDFに変換すると次のようになる。(Turtle形式)
@prefix shogun: <http://example.org/shogun_schema#> .
:001 shogun:名前 "徳川 家康" ;
shogun:年齢 75 .
:002 shogun:名前 "徳川 秀忠" ;
shogun:年齢 54 .
:003 shogun:名前 "徳川 家光" ;
shogun:年齢 48 .
上記で使っている shogun:名前 や shogun:年齢 は、私が適当に定義した語彙であり、こういった語彙は「独自定義語彙」などと呼ばれている。
独自定義語彙は、政府組織や権威のある学術機関がきっちり定義したものであれば再利用性が生じるが、そうでなければ、作成者限りの「狭い語彙」とみなされる。
上記のような、すべてが「狭い語彙」のRDFの価値は無に等しく、元データのエクセル表のほうがよっぽど汎用的で分かりやすい。
次に、世界標準の語彙を使って書き直したRDFを示す。
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
:001 foaf:name "徳川 家康" ;
foaf:age 75 .
:002 foaf:name "徳川 秀忠" ;
foaf:age 54 .
:003 foaf:name "徳川 家光" ;
foaf:age 48 .
上記であれば、誰もが納得の「開かれた」RDFであることが一目瞭然だ。
しかしながら、作成者のセンスによっては、次のように書かれることもあろう。
@prefix schema: <http://schema.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
:001 schema:familyName "徳川" ;
schema:givenName "家康" ;
foaf:age 75 .
:002 schema:familyName "徳川" ;
schema:givenName "秀忠" ;
foaf:age 54 .
:003 schema:familyName "徳川" ;
schema:givenName "家光" ;
foaf:age 48 .
これはこれで、世界標準のRDFとしてきちんと成立している。
じゃあ、どっちが正しいの、と聞かれると、どっちも正しい、としか言いようがない。
(日本語)これはラーメンです。
(英語) This is a ramen.
(フランス語) C'est un ramen.
(日本語・大阪弁)これはラーメンやねん。
(日本語・博多弁)これはラーメンばい。
上記がどれも正しいのと一緒。使っている言語や方言が違うだけだ。
これらを踏まえた上で、さて、共通語彙基盤はどこを目指しているのか。
我々ユーザーは、どう理解し、どう活用したらいいのか。
IMIのホームページには次の記載がある。
『国・地方公共団体等が公開するデータの標準化を通じて、データの作成、流通、交換を容易にし促進するための基盤で、データに「価値」を生み出すことを目指しています。』
ここ数年で、国や自治体のオープンデータ事業はかなり進み、官が保有している膨大なデータが、二次利用可能な形で、徐々に公開されるようになってきた。
その一方で、その提供されるデータ群は、省庁や自治体ごとに形式がバラバラで、使い勝手が良いとは言い難い。
これらのまとまりのないデータを標準化し、ユーザーが使いやすいものにするためのアプローチの一つが「政府推奨データセット」であり、もう一つがこの共通語彙基盤だ。
徳川将軍のデータに戻って、その二つの役割分担を考えてみる。
【政府推奨データセット】
⇒ 徳川将軍データセットに必要な項目は「名前」及び「年齢」であると決める。
【共通語彙基盤】
⇒ 徳川将軍データセットにおける「名前」及び「年齢」という各項目が、具体的に何を示しているかを明確にする。
もう少し具体的にいうと、共通語彙基盤を用いて、例えば「ものごとの名前」を表現するときは、その対象の性質により表現方法が変わる。
(人の名前の場合) 人型>氏名型>ic:氏名>ic:姓名 ⇒ 徳川家康
(組織の名称の場合) 組織型>名称型>ic:表記 ⇒ 加賀藩
(イベントの名称の場合)イベント型>名称型>ic:表記 ⇒ 大政奉還
このような形で、対象項目が何を示しているかをきっちり指し示し、曖昧さを排除した表現とするのが、共通語彙基盤の役割であろう。
【共通語彙基盤の適用例】
@prefix ic: <http://imi.go.jp/ns/core/rdf#> .
:001 a ic:人型 ;
ic:氏名 [ ic:姓名 "徳川 家康"^^xsd:string ] ;
ic:年齢 [ ic:数値 "75"^^xsd:integer ] .
:002 a ic:人型 ;
ic:氏名 [ ic:姓名 "徳川 秀忠"^^xsd:string ] ;
ic:年齢 [ ic:数値 "54"^^xsd:integer ] .
:003 a ic:人型 ;
ic:氏名 [ ic:姓名 "徳川 家光"^^xsd:string ] ;
ic:年齢 [ ic:数値 "48"^^xsd:integer ] .
曖昧さや多様性といったものは必ずしも悪いものではなく、それがあるからこそ発展があり、新しい知見が生み出されていく。
しかし、曖昧さや多様性が障害となる分野もある。コンピューターのプログラムや、法律などがそれにあたる。
もし刑法に「悪いやつには、罰を与える」と書いてあったら、何をしたらどんな罰を受けるのか全く分からないし、戦前の治安維持法のような運用も可能となる。
そのような曖昧さを回避し、「ものを盗んだ人には、懲役3年の刑罰を与える」と具体的に示すのが、共通語彙基盤の本質的な意義だろう。
法の執行者であり、公共性や中立性が求められる公務の分野においては、共通語彙基盤の思想は比較的馴染みやすい。公的機関が共通語彙基盤を利用する土壌は少しずつ整ってきており、次は実践が必要な段階だ。
そのためには、IPAは、共通語彙基盤の技術情報や活用ツールの充実だけでなく、背景にある思想の周知や、利用者のメリットの広報に、これまで以上にリソースを割くべきだろう。
共通語彙基盤の魅力を存分に語ることができる「IMI伝道師」を育成して、日本各地を巡ってもらうのもいいかもしれないなぁ。
例えば、次のような表形式のデータがあるとする。
| 名前 | 年齢(享年) |
|---|---|
| 徳川 家康 |
75
|
| 徳川 秀忠 |
54
|
| 徳川 家光 |
48
|
上記の表データを、汎用性を考慮せず、単純にRDFに変換すると次のようになる。(Turtle形式)
@prefix shogun: <http://example.org/shogun_schema#> .
:001 shogun:名前 "徳川 家康" ;
shogun:年齢 75 .
:002 shogun:名前 "徳川 秀忠" ;
shogun:年齢 54 .
:003 shogun:名前 "徳川 家光" ;
shogun:年齢 48 .
上記で使っている shogun:名前 や shogun:年齢 は、私が適当に定義した語彙であり、こういった語彙は「独自定義語彙」などと呼ばれている。
独自定義語彙は、政府組織や権威のある学術機関がきっちり定義したものであれば再利用性が生じるが、そうでなければ、作成者限りの「狭い語彙」とみなされる。
上記のような、すべてが「狭い語彙」のRDFの価値は無に等しく、元データのエクセル表のほうがよっぽど汎用的で分かりやすい。
次に、世界標準の語彙を使って書き直したRDFを示す。
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
:001 foaf:name "徳川 家康" ;
foaf:age 75 .
:002 foaf:name "徳川 秀忠" ;
foaf:age 54 .
:003 foaf:name "徳川 家光" ;
foaf:age 48 .
上記であれば、誰もが納得の「開かれた」RDFであることが一目瞭然だ。
しかしながら、作成者のセンスによっては、次のように書かれることもあろう。
@prefix schema: <http://schema.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
:001 schema:familyName "徳川" ;
schema:givenName "家康" ;
foaf:age 75 .
:002 schema:familyName "徳川" ;
schema:givenName "秀忠" ;
foaf:age 54 .
:003 schema:familyName "徳川" ;
schema:givenName "家光" ;
foaf:age 48 .
これはこれで、世界標準のRDFとしてきちんと成立している。
じゃあ、どっちが正しいの、と聞かれると、どっちも正しい、としか言いようがない。
(日本語)これはラーメンです。
(英語) This is a ramen.
(フランス語) C'est un ramen.
(日本語・大阪弁)これはラーメンやねん。
(日本語・博多弁)これはラーメンばい。
上記がどれも正しいのと一緒。使っている言語や方言が違うだけだ。
これらを踏まえた上で、さて、共通語彙基盤はどこを目指しているのか。
我々ユーザーは、どう理解し、どう活用したらいいのか。
IMIのホームページには次の記載がある。
『国・地方公共団体等が公開するデータの標準化を通じて、データの作成、流通、交換を容易にし促進するための基盤で、データに「価値」を生み出すことを目指しています。』
ここ数年で、国や自治体のオープンデータ事業はかなり進み、官が保有している膨大なデータが、二次利用可能な形で、徐々に公開されるようになってきた。
その一方で、その提供されるデータ群は、省庁や自治体ごとに形式がバラバラで、使い勝手が良いとは言い難い。
これらのまとまりのないデータを標準化し、ユーザーが使いやすいものにするためのアプローチの一つが「政府推奨データセット」であり、もう一つがこの共通語彙基盤だ。
徳川将軍のデータに戻って、その二つの役割分担を考えてみる。
【政府推奨データセット】
⇒ 徳川将軍データセットに必要な項目は「名前」及び「年齢」であると決める。
【共通語彙基盤】
⇒ 徳川将軍データセットにおける「名前」及び「年齢」という各項目が、具体的に何を示しているかを明確にする。
もう少し具体的にいうと、共通語彙基盤を用いて、例えば「ものごとの名前」を表現するときは、その対象の性質により表現方法が変わる。
(人の名前の場合) 人型>氏名型>ic:氏名>ic:姓名 ⇒ 徳川家康
(組織の名称の場合) 組織型>名称型>ic:表記 ⇒ 加賀藩
(イベントの名称の場合)イベント型>名称型>ic:表記 ⇒ 大政奉還
このような形で、対象項目が何を示しているかをきっちり指し示し、曖昧さを排除した表現とするのが、共通語彙基盤の役割であろう。
【共通語彙基盤の適用例】
@prefix ic: <http://imi.go.jp/ns/core/rdf#> .
:001 a ic:人型 ;
ic:氏名 [ ic:姓名 "徳川 家康"^^xsd:string ] ;
ic:年齢 [ ic:数値 "75"^^xsd:integer ] .
:002 a ic:人型 ;
ic:氏名 [ ic:姓名 "徳川 秀忠"^^xsd:string ] ;
ic:年齢 [ ic:数値 "54"^^xsd:integer ] .
:003 a ic:人型 ;
ic:氏名 [ ic:姓名 "徳川 家光"^^xsd:string ] ;
ic:年齢 [ ic:数値 "48"^^xsd:integer ] .
曖昧さや多様性といったものは必ずしも悪いものではなく、それがあるからこそ発展があり、新しい知見が生み出されていく。
しかし、曖昧さや多様性が障害となる分野もある。コンピューターのプログラムや、法律などがそれにあたる。
もし刑法に「悪いやつには、罰を与える」と書いてあったら、何をしたらどんな罰を受けるのか全く分からないし、戦前の治安維持法のような運用も可能となる。
そのような曖昧さを回避し、「ものを盗んだ人には、懲役3年の刑罰を与える」と具体的に示すのが、共通語彙基盤の本質的な意義だろう。
法の執行者であり、公共性や中立性が求められる公務の分野においては、共通語彙基盤の思想は比較的馴染みやすい。公的機関が共通語彙基盤を利用する土壌は少しずつ整ってきており、次は実践が必要な段階だ。
そのためには、IPAは、共通語彙基盤の技術情報や活用ツールの充実だけでなく、背景にある思想の周知や、利用者のメリットの広報に、これまで以上にリソースを割くべきだろう。
共通語彙基盤の魅力を存分に語ることができる「IMI伝道師」を育成して、日本各地を巡ってもらうのもいいかもしれないなぁ。
2018年6月3日日曜日
IMI意見交換会
6月1日、IPAのIMI意見交換会で講演させていただいた。

何をしゃべろうか悩んだが、やはり共通語彙基盤ネタがウケるだろうと考え、共通語彙基盤と Linked Open Data という超壮大なテーマを、超コンパクトにまとめてしゃべってきた。
しゃべったのは、「共通語彙基盤って、ぶっちゃけ難しすぎるよね」みたいな、身も蓋もない内容。
お気を悪くされた関係者もいたと思う。すいませんでした。
しかし今回の意見交換会、IPAの本気が感じられる素晴らしい会で、参加してほんとに良かったと感じている。データをめぐる最新の動向を知る良い機会ともなり、非常に勉強になった。
意外だったのは、拙作の共通語彙基盤ラーメンデータセットがニッチに人気があったこと。鯖江の福野さんの一日一創ブログでも紹介していただいた。
福野さんの、共通語彙基盤に対する感性はさすがに鋭く、ユーザーとして、また技術者としての様々な見解は、非常に共感できるものだった。
全角日本語の語彙は、グローバル社会の中で受け入れられるのは難しいのではないかという問題提起、Schema.orgとの互換性、などなど。
多様性と信頼の共存、まさにそれが必要だろう。
みんなの幸せのための共通語彙基盤の発展に、私も、少しでも力添えができたらと考えている。

何をしゃべろうか悩んだが、やはり共通語彙基盤ネタがウケるだろうと考え、共通語彙基盤と Linked Open Data という超壮大なテーマを、超コンパクトにまとめてしゃべってきた。
しゃべったのは、「共通語彙基盤って、ぶっちゃけ難しすぎるよね」みたいな、身も蓋もない内容。
お気を悪くされた関係者もいたと思う。すいませんでした。
しかし今回の意見交換会、IPAの本気が感じられる素晴らしい会で、参加してほんとに良かったと感じている。データをめぐる最新の動向を知る良い機会ともなり、非常に勉強になった。
意外だったのは、拙作の共通語彙基盤ラーメンデータセットがニッチに人気があったこと。鯖江の福野さんの一日一創ブログでも紹介していただいた。
福野さんの、共通語彙基盤に対する感性はさすがに鋭く、ユーザーとして、また技術者としての様々な見解は、非常に共感できるものだった。
全角日本語の語彙は、グローバル社会の中で受け入れられるのは難しいのではないかという問題提起、Schema.orgとの互換性、などなど。
多様性と信頼の共存、まさにそれが必要だろう。
みんなの幸せのための共通語彙基盤の発展に、私も、少しでも力添えができたらと考えている。
2018年4月30日月曜日
ドメインをとった
このたび、mirko.jp のドメインを取得し、公共オープンデータ利活用研究室 mirko のホームページに割り当てた。
https://www.mirko.jp/
公共オープンデータ利活用研究室 mirko は、ネットオウルのレンタルサーバーで運営している。
ネットオウルは、地元の京都市の会社なので、個人的に応援しているという理由もある。
これまでは、ネットオウルの「ミニバード」というサービスのサブドメインに、僕のニックネーム mirko を割り当てて mirko.minibird.jp としていた。
上記のURLに特に不満はなかったのだが、やっぱり、ずっと使える永続的なURLがいいなと思い、ネットオウルから独自ドメインの取得申請を行った。
何の苦労もなく、5分で手続き完了。
浸透するまで半日ほど待ち、リダイレクトかけて、グーグル検索のサイト引っ越しをちょいちょいと。はい完成。簡単なもんだ。
ドメイン取得で思い出すのは、今から20数年前、まだWEB黎明期だったころ、仲介業者を介さず、苦労して自力でドメインをとったこと。
とったドメインは pospe.com 。
当時、ポストペット(通称ポスペ)というメーラーが大流行していて、私はそれをマニアックに解析するという、「ポストペットマニアックス」というサイトを、そのドメインで運営していた。若かりし頃の黒歴史の一つだ。
そのポストペットマニアックス、結構人気もあって、2年ほど楽しく遊んでいたのだが、当時、お金が全然無くなっちゃって、生活のため、やむ無く pospe.com をドメイン屋に売り払った。
まだポストペット人気が高い時期だったので、僕のポスペコムは8万円くらいで売れたように記憶している。おかげで、何とか生き延びることができた。
(今の時代なら広告収入でウハウハ生活ができたのになぁ…)
そのポスペコム、今はどうなってるんだろうと覗いてみたら、こんなだった。
http://www.pospe.com/
兵どもが夢の跡かな(笑)
https://www.mirko.jp/
公共オープンデータ利活用研究室 mirko は、ネットオウルのレンタルサーバーで運営している。
ネットオウルは、地元の京都市の会社なので、個人的に応援しているという理由もある。
これまでは、ネットオウルの「ミニバード」というサービスのサブドメインに、僕のニックネーム mirko を割り当てて mirko.minibird.jp としていた。
上記のURLに特に不満はなかったのだが、やっぱり、ずっと使える永続的なURLがいいなと思い、ネットオウルから独自ドメインの取得申請を行った。
何の苦労もなく、5分で手続き完了。
浸透するまで半日ほど待ち、リダイレクトかけて、グーグル検索のサイト引っ越しをちょいちょいと。はい完成。簡単なもんだ。
ドメイン取得で思い出すのは、今から20数年前、まだWEB黎明期だったころ、仲介業者を介さず、苦労して自力でドメインをとったこと。
とったドメインは pospe.com 。
当時、ポストペット(通称ポスペ)というメーラーが大流行していて、私はそれをマニアックに解析するという、「ポストペットマニアックス」というサイトを、そのドメインで運営していた。若かりし頃の黒歴史の一つだ。
そのポストペットマニアックス、結構人気もあって、2年ほど楽しく遊んでいたのだが、当時、お金が全然無くなっちゃって、生活のため、やむ無く pospe.com をドメイン屋に売り払った。
まだポストペット人気が高い時期だったので、僕のポスペコムは8万円くらいで売れたように記憶している。おかげで、何とか生き延びることができた。
(今の時代なら広告収入でウハウハ生活ができたのになぁ…)
そのポスペコム、今はどうなってるんだろうと覗いてみたら、こんなだった。
http://www.pospe.com/
兵どもが夢の跡かな(笑)
2018年4月28日土曜日
統計LODの家計調査データセット
先日の、統計LODのデータセット追加リリースで、家計調査 が追加された。
家計調査は、政府が消費者物価指数をつくるときの資料にしたり、景気動向を知る指標としたり、様々な(真面目な)目的で使われている。
その家計調査、僕らのような一般の統計ユーザーが面白いと思う点は、食べ物の品目ごとに、都市別で、世帯当たりの支出金額や消費数量が調査されているところ。
「京都人はパンが好き」とか、「餃子日本一はどこか?」の元ネタだ。
ただし、家計調査は標本調査であり、しかも都市別となると標本数がかなり少ないので、統計としての定量的な信頼性はイマイチだ。
まあ、それをきちんと踏まえた上で、政府がお墨付きを与えたトリビアネタ との位置づけでどんどん使えば、政府統計の普及啓発にも一役買うことができる、ということだ。
さっそく、スパークルをたたいてデータセットを覗いてみる。
まずは「調査年月」を調べるクエリ。
2005年9月以降の毎月のデータがあることがわかる。
ちなみに、家計調査は「家計調査年報」という形で、1年間の合計値や平均値が公表されているが、統計LODには年報データは無いようでガッカリ。
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX g00200561-dimension: <http://data.e-stat.go.jp/lod/ontology/g00200561/dimension/2015/>
PREFIX g00200561-code: <http://data.e-stat.go.jp/lod/ontology/g00200561/code/2015/>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
SELECT DISTINCT ?yearmonth
WHERE {
?s qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200561/d0003103532> ;
g00200561-dimension:ieClassification g00200561-code:ieClassification-1_1_2 ;
cd-dimension:timePeriod ?yearmonth .
} ORDER BY DESC(?yearmonth)
次は、2017年7月のパンへの支出金額を、対象自治体ごとに調べるクエリだ。
都道府県庁所在市 + その他の政令市 + 全国値 の、計53の観測値が表示される。
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX g00200561-dimension: <http://data.e-stat.go.jp/lod/ontology/g00200561/dimension/2015/>
PREFIX g00200561-code: <http://data.e-stat.go.jp/lod/ontology/g00200561/code/2015/>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX estat-measure: <http://data.e-stat.go.jp/lod/ontology/measure/>
PREFIX ic: <http://imi.go.jp/ns/core/rdf#>
select ?citycode ?cityname ?o
where {
?s qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200561/d0003103532> ;
g00200561-dimension:ieClassification g00200561-code:ieClassification-1_1_2 ;
cd-dimension:timePeriod "2017-07"^^xsd:gYearMonth ;
sdmx-dimension:refArea ?citycode ;
estat-measure:moneyAmount ?o .
?citycode ic:表記 ?cityname .
} ORDER BY ASC(?citycode)
これらのクエリをアプリに組み込んで、面白いものができないかなーと現在検討中。
家計調査データセットについて、総務省統計局へお願いしたいのは、次の2点。
ひとつ目は「年報」のデータも入れてほしいこと。
ふたつ目は、支出金額だけでなく「消費数量」のデータも欲しいこと。
よろしくお願いします m(__)m
家計調査は、政府が消費者物価指数をつくるときの資料にしたり、景気動向を知る指標としたり、様々な(真面目な)目的で使われている。
その家計調査、僕らのような一般の統計ユーザーが面白いと思う点は、食べ物の品目ごとに、都市別で、世帯当たりの支出金額や消費数量が調査されているところ。
「京都人はパンが好き」とか、「餃子日本一はどこか?」の元ネタだ。
ただし、家計調査は標本調査であり、しかも都市別となると標本数がかなり少ないので、統計としての定量的な信頼性はイマイチだ。
まあ、それをきちんと踏まえた上で、政府がお墨付きを与えたトリビアネタ との位置づけでどんどん使えば、政府統計の普及啓発にも一役買うことができる、ということだ。
さっそく、スパークルをたたいてデータセットを覗いてみる。
まずは「調査年月」を調べるクエリ。
2005年9月以降の毎月のデータがあることがわかる。
ちなみに、家計調査は「家計調査年報」という形で、1年間の合計値や平均値が公表されているが、統計LODには年報データは無いようでガッカリ。
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX g00200561-dimension: <http://data.e-stat.go.jp/lod/ontology/g00200561/dimension/2015/>
PREFIX g00200561-code: <http://data.e-stat.go.jp/lod/ontology/g00200561/code/2015/>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
SELECT DISTINCT ?yearmonth
WHERE {
?s qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200561/d0003103532> ;
g00200561-dimension:ieClassification g00200561-code:ieClassification-1_1_2 ;
cd-dimension:timePeriod ?yearmonth .
} ORDER BY DESC(?yearmonth)
次は、2017年7月のパンへの支出金額を、対象自治体ごとに調べるクエリだ。
都道府県庁所在市 + その他の政令市 + 全国値 の、計53の観測値が表示される。
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX g00200561-dimension: <http://data.e-stat.go.jp/lod/ontology/g00200561/dimension/2015/>
PREFIX g00200561-code: <http://data.e-stat.go.jp/lod/ontology/g00200561/code/2015/>
PREFIX cd-dimension: <http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX estat-measure: <http://data.e-stat.go.jp/lod/ontology/measure/>
PREFIX ic: <http://imi.go.jp/ns/core/rdf#>
select ?citycode ?cityname ?o
where {
?s qb:dataSet <http://data.e-stat.go.jp/lod/dataset/g00200561/d0003103532> ;
g00200561-dimension:ieClassification g00200561-code:ieClassification-1_1_2 ;
cd-dimension:timePeriod "2017-07"^^xsd:gYearMonth ;
sdmx-dimension:refArea ?citycode ;
estat-measure:moneyAmount ?o .
?citycode ic:表記 ?cityname .
} ORDER BY ASC(?citycode)
これらのクエリをアプリに組み込んで、面白いものができないかなーと現在検討中。
家計調査データセットについて、総務省統計局へお願いしたいのは、次の2点。
ひとつ目は「年報」のデータも入れてほしいこと。
ふたつ目は、支出金額だけでなく「消費数量」のデータも欲しいこと。
よろしくお願いします m(__)m
2018年4月27日金曜日
ブログを作ってみた。
理由は、自治体なんでもランキング with 統計LOD の おまけコラム を、ブログに移したほうが合理的かなー、と思ったから。
ブログも、今時はいろんなサービスがよりどりみどりで迷ってしまう。
FC2とかアメブロとかはてなブログとか…
悩んだ結果、僕はグーグルのブログサービス Blogger にした。
検索でもっと上位に来るブログサービスも色々ありそうだが、僕のブログはただの独り言日記みたいなものなので、あまり読まれなくてもいいし、何より広告が無いのがイイ!
グーグルなので、親サイト自体がつぶれて、サービスが停止されることもまずないだろうし。
(グーグルがブログサービスを突然やめちゃう可能性はあるが…)
ワードプレスを使って自分で作ろうとも思ったが、最近忙しくて、めんどくさくなって諦めてしまった…
時間ができて、ワードプレスのほうが良さそうなら、そのうち乗り換えるかも。
ブログも、今時はいろんなサービスがよりどりみどりで迷ってしまう。
FC2とかアメブロとかはてなブログとか…
悩んだ結果、僕はグーグルのブログサービス Blogger にした。
検索でもっと上位に来るブログサービスも色々ありそうだが、僕のブログはただの独り言日記みたいなものなので、あまり読まれなくてもいいし、何より広告が無いのがイイ!
グーグルなので、親サイト自体がつぶれて、サービスが停止されることもまずないだろうし。
(グーグルがブログサービスを突然やめちゃう可能性はあるが…)
ワードプレスを使って自分で作ろうとも思ったが、最近忙しくて、めんどくさくなって諦めてしまった…
時間ができて、ワードプレスのほうが良さそうなら、そのうち乗り換えるかも。
2018年4月23日月曜日
「S」をめぐる、IPAと統計局のすれ違い (2018.4.15)
2018年4月13日、統計LODのデータが拡充された。
このWEBアプリで使っている「社会・人口統計体系」のデータも、今回たくさん追加されたので、さっそくプログラムを修正し、追加されたデータも取得できるようにした。
市区町村レベルのデータが大幅に増えたので、一度お試しあれ。
(データが増えた分、前よりさらに重くなったような気がするのは、きっと気のせいだろう…)
さて、統計LODでは、今回、データの拡充と同時に、共通語彙基盤の名前空間URIを、旧URIから新URIに置き換える修正を実施した。
私が以前から要望していたことを実現していただき、感謝の意をお伝えしたい。
私はさっそく、この修正に合わせ、「自治体なんでもランキング with 統計LOD」で使っているSPARQLクエリ内の、共通語彙基盤URIを書き換えることにした。
「ん? ……!」
調べてみると、統計LODで使われている名前空間URIは次のようになっている。
http://imi.go.jp/ns/core/rdf# (ここ参照)
一方、IPAが使ってくれ、と言っているURIは次のものだ。
https://imi.go.jp/ns/core/rdf# (ここ参照)
…あー、恐れていたことが起きてしまった!
IPAからしたら、ちゃんとリダイレクトかけてるから別にいーじゃん、という考えが根っこにあるのかもしれないが、私のようなオープンデータ作成者や、アプリケーション開発者にとっては、決して看過できない大問題だ。
なぜなら、http://imi.go.jp/ns/core/rdf# と https://imi.go.jp/ns/core/rdf# は、全く別の文字列だから。
データとデータがつながる Linked Data の特性を生かすための「フェデレーテッドクエリ」も、これでは全く真価を発揮できず、つながるものもつながらない。スパークラーの皆さんなら、きっと共感していただけるかと思う。
このIPAと統計LODとの交通事故における「過失割合」を考えると、私は8:2でIPAが悪いと思う。
(統計LOD側の不注意も少しはあるが…)
共通語彙基盤における、RDF用名前空間はまず次のURIからスタートした。
http://imi.ipa.go.jp/ns/core/rdf#
その後、次のURIに変更された。
http://imi.go.jp/ns/core/rdf#
最初のものはIPAドメインのサブドメインとしてIMIが設定されていたが、名前空間URIの不変性を担保するために、IPAドメインとは切り離し、IMI独自ドメインとして設定するのが望ましいということだろう。その意図はよく分かる。
その後、今度は以下のURIに変更された。
https://imi.go.jp/ns/core/rdf#
最近は猫も杓子もSSLで、SSLにあらずんばWEBにあらず、という勢いだ。
IPAは我が国の情報処理を司る大本営。SSL対応とするのは当たり前と言えば当たり前。
大切なのは、結果として3種類できてしまった名前空間URIを、ユーザーに対しどのように周知徹底し、最新のURIにいかに導いていくかだ。
IPAはそこを大事にしなければならないというのに、最新のコア語彙バージョン2.4.1のページで提示されているRDFスキーマやJSON-LDコンテキストを見ると、驚くべきことに、いまだに「s」がついていない。(2018年4月15日現在)
これでは、統計LODサイドが勘違いするのもむべなるかな。はっきり言ってこれはIPAの怠慢だと言わざるを得ない。起こるべくして起きた事故だ。
共通語彙の目的は、みんなが使う語彙の共通化。共通語彙基盤はみんなのハブ空港。
共通化どころか、自らの手で基準を乱立させ、周知徹底もせず、リダイレクトをかけるだけで満足しているようなデリカシーのない共通語彙からは、ユーザーはどんどん離れていくのが目に見えている。
共通語彙基盤を本気で流行らせたいのなら、もっとちゃんとしてください!頼みますよ!!
このWEBアプリで使っている「社会・人口統計体系」のデータも、今回たくさん追加されたので、さっそくプログラムを修正し、追加されたデータも取得できるようにした。
市区町村レベルのデータが大幅に増えたので、一度お試しあれ。
(データが増えた分、前よりさらに重くなったような気がするのは、きっと気のせいだろう…)
さて、統計LODでは、今回、データの拡充と同時に、共通語彙基盤の名前空間URIを、旧URIから新URIに置き換える修正を実施した。
私が以前から要望していたことを実現していただき、感謝の意をお伝えしたい。
私はさっそく、この修正に合わせ、「自治体なんでもランキング with 統計LOD」で使っているSPARQLクエリ内の、共通語彙基盤URIを書き換えることにした。
「ん? ……!」
調べてみると、統計LODで使われている名前空間URIは次のようになっている。
http://imi.go.jp/ns/core/rdf# (ここ参照)
一方、IPAが使ってくれ、と言っているURIは次のものだ。
https://imi.go.jp/ns/core/rdf# (ここ参照)
…あー、恐れていたことが起きてしまった!
IPAからしたら、ちゃんとリダイレクトかけてるから別にいーじゃん、という考えが根っこにあるのかもしれないが、私のようなオープンデータ作成者や、アプリケーション開発者にとっては、決して看過できない大問題だ。
なぜなら、http://imi.go.jp/ns/core/rdf# と https://imi.go.jp/ns/core/rdf# は、全く別の文字列だから。
データとデータがつながる Linked Data の特性を生かすための「フェデレーテッドクエリ」も、これでは全く真価を発揮できず、つながるものもつながらない。スパークラーの皆さんなら、きっと共感していただけるかと思う。
このIPAと統計LODとの交通事故における「過失割合」を考えると、私は8:2でIPAが悪いと思う。
(統計LOD側の不注意も少しはあるが…)
共通語彙基盤における、RDF用名前空間はまず次のURIからスタートした。
http://imi.ipa.go.jp/ns/core/rdf#
その後、次のURIに変更された。
http://imi.go.jp/ns/core/rdf#
最初のものはIPAドメインのサブドメインとしてIMIが設定されていたが、名前空間URIの不変性を担保するために、IPAドメインとは切り離し、IMI独自ドメインとして設定するのが望ましいということだろう。その意図はよく分かる。
その後、今度は以下のURIに変更された。
https://imi.go.jp/ns/core/rdf#
最近は猫も杓子もSSLで、SSLにあらずんばWEBにあらず、という勢いだ。
IPAは我が国の情報処理を司る大本営。SSL対応とするのは当たり前と言えば当たり前。
大切なのは、結果として3種類できてしまった名前空間URIを、ユーザーに対しどのように周知徹底し、最新のURIにいかに導いていくかだ。
IPAはそこを大事にしなければならないというのに、最新のコア語彙バージョン2.4.1のページで提示されているRDFスキーマやJSON-LDコンテキストを見ると、驚くべきことに、いまだに「s」がついていない。(2018年4月15日現在)
これでは、統計LODサイドが勘違いするのもむべなるかな。はっきり言ってこれはIPAの怠慢だと言わざるを得ない。起こるべくして起きた事故だ。
共通語彙の目的は、みんなが使う語彙の共通化。共通語彙基盤はみんなのハブ空港。
共通化どころか、自らの手で基準を乱立させ、周知徹底もせず、リダイレクトをかけるだけで満足しているようなデリカシーのない共通語彙からは、ユーザーはどんどん離れていくのが目に見えている。
共通語彙基盤を本気で流行らせたいのなら、もっとちゃんとしてください!頼みますよ!!
東京南多摩5市賞に寄せて - 自治体の真の実力比較 - (2018.3.3)
LODチャレンジ2017の他の方の受賞作品を見ようと思い、受賞作品発表のプレスリリースを見ていたら、当アプリが東京南多摩5市賞を受賞していることを知ってビックリ!
多摩5市の特産品まで頂けるとのこと。本当にありがとうございます m(__)m
私は愛知県出身で京都在住。多摩5市には縁もゆかりもなく、今まで生きてきた。 しかし、多摩5市に頂いたこのサプライズの恩返しをしなくては、と思い、急遽『多摩5市ボタン』を追加した。 こういう小回りが利く点が、個人の趣味でやっている良いところかも。
さて、次のグラフをご覧いただきたい。
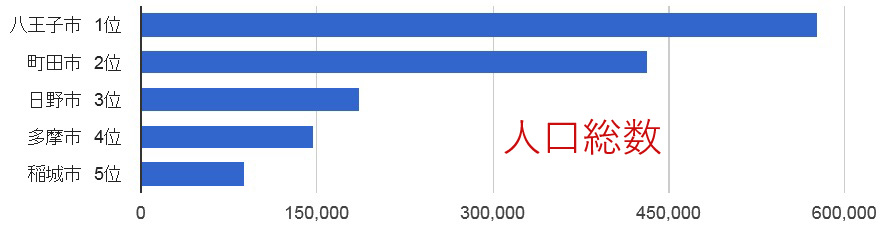
これは多摩5市の人口総数を比較したグラフだ。 トップの八王子市と最下位の稲城市では、6倍以上の差がある。
「自治体なんでもランキング with 統計LOD」には欠点があり、八王子市と稲城市のように、そもそも自治体の規模が違う場合、その自治体の「真の実力」を比較することができない。
例えば、自治体の将来を担う15歳未満の子供がどれだけいるか。 総数で見た場合は、次のグラフのように、分母がでかい八王子市が多いに決まっている。
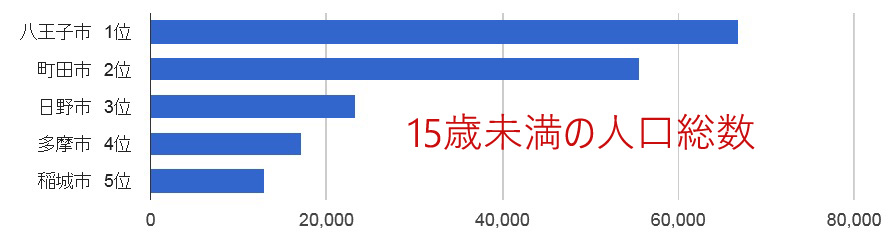
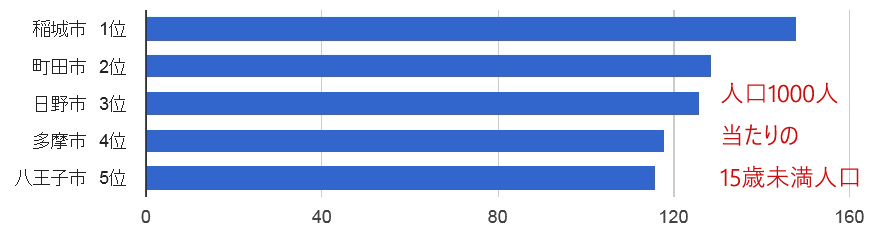
真の実力を測るには、15歳未満の子供の「割合」が重要だ。 そこで、「人口1000人当たりの値」で表示するボタンも作成した。 そのボタンを用い、15歳未満の子供のグラフを作成すると、なんと稲城市がトップに躍り出た。稲城市は若年層の割合が高いようだ。
次のグラフは昼間人口の夜間人口に対する比率を示したものだ。
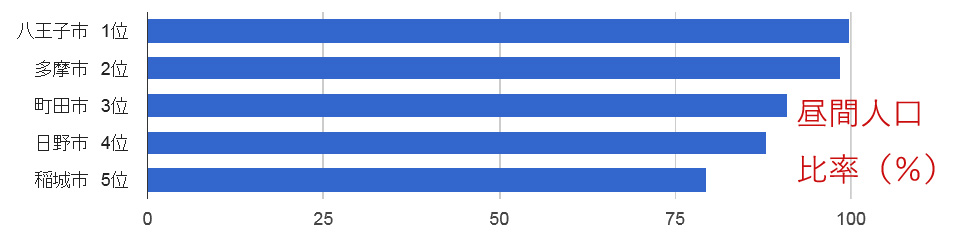
「夜間人口」とは、そこに居住している人口のこと。一方「昼間人口」とは、夜間人口から通勤・通学者を差し引きした人口のことだ。 このグラフを見ると、稲城市は昼間人口が少ない(=夜間人口が多い)ことから、23区などのベッドタウンになっており、子育て世帯が多いことが推測できる。子供が多い理由はこのあたりにあるのだろう。
視点を変えて、1000人当たりの市町村税収納済額(≒税収)を見てみよう。
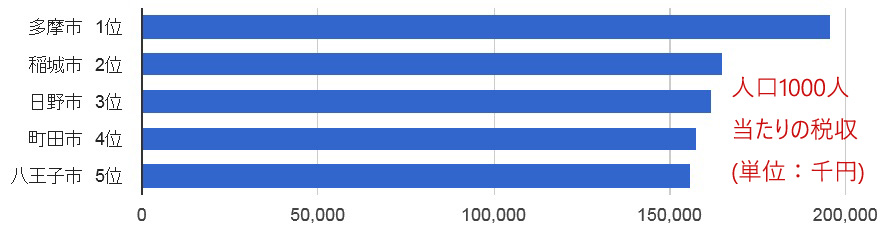
多摩市がダントツで、稲城市、日野市と続くことが分かる。
以上、総数だけでは分からない自治体の実力と、地域分析の手法を少しだけ紹介させていただいた。 なお、このアプリの人口1000人当たりの計算は、すべて2015年の国勢調査人口により割り出したものであるため、各統計の調査年次により、正しい値と乖離する場合があることをご了承いただきたい。
多摩5市のことを全く知らなかった私が、LODチャレンジをきっかけに、5市と繋がりを持つことができ、とても嬉しく思っている。八王子市、町田市、日野市、多摩市、稲城市の関係者の皆様に、感謝の意をお伝え申し上げたい。
多摩5市の特産品まで頂けるとのこと。本当にありがとうございます m(__)m
私は愛知県出身で京都在住。多摩5市には縁もゆかりもなく、今まで生きてきた。 しかし、多摩5市に頂いたこのサプライズの恩返しをしなくては、と思い、急遽『多摩5市ボタン』を追加した。 こういう小回りが利く点が、個人の趣味でやっている良いところかも。
さて、次のグラフをご覧いただきたい。
これは多摩5市の人口総数を比較したグラフだ。 トップの八王子市と最下位の稲城市では、6倍以上の差がある。
「自治体なんでもランキング with 統計LOD」には欠点があり、八王子市と稲城市のように、そもそも自治体の規模が違う場合、その自治体の「真の実力」を比較することができない。
例えば、自治体の将来を担う15歳未満の子供がどれだけいるか。 総数で見た場合は、次のグラフのように、分母がでかい八王子市が多いに決まっている。
真の実力を測るには、15歳未満の子供の「割合」が重要だ。 そこで、「人口1000人当たりの値」で表示するボタンも作成した。 そのボタンを用い、15歳未満の子供のグラフを作成すると、なんと稲城市がトップに躍り出た。稲城市は若年層の割合が高いようだ。
次のグラフは昼間人口の夜間人口に対する比率を示したものだ。
「夜間人口」とは、そこに居住している人口のこと。一方「昼間人口」とは、夜間人口から通勤・通学者を差し引きした人口のことだ。 このグラフを見ると、稲城市は昼間人口が少ない(=夜間人口が多い)ことから、23区などのベッドタウンになっており、子育て世帯が多いことが推測できる。子供が多い理由はこのあたりにあるのだろう。
視点を変えて、1000人当たりの市町村税収納済額(≒税収)を見てみよう。
多摩市がダントツで、稲城市、日野市と続くことが分かる。
以上、総数だけでは分からない自治体の実力と、地域分析の手法を少しだけ紹介させていただいた。 なお、このアプリの人口1000人当たりの計算は、すべて2015年の国勢調査人口により割り出したものであるため、各統計の調査年次により、正しい値と乖離する場合があることをご了承いただきたい。
多摩5市のことを全く知らなかった私が、LODチャレンジをきっかけに、5市と繋がりを持つことができ、とても嬉しく思っている。八王子市、町田市、日野市、多摩市、稲城市の関係者の皆様に、感謝の意をお伝え申し上げたい。
統計LODのSPARQLクエリ研究 (2017.12.28)
自治体なんでもランキング with 統計LOD に必要な情報を、一挙に入手するクエリは以下の通り。
統計LOD の SPARQL Endpoint はこちら。クエリをコピペして一度お試しあれ。
なお、アプリ上では、統計指標(述語 g00200502-dimension:indicator に対する 目的語)については、ドロップダウンリストで選択したものをセットするが、ここでは便宜的に「g00200502-code:indicator-A1101」(人口総数)にしている。
PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?year ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod ?year ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
?areacode sacs:administrativeClass sacs:Prefecture ;
ic:表記 ?pref .
} ORDER BY DESC(?year) DESC(?observation)
PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?city ?year ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod ?year ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
?areacode sacs:administrativeClass sacs:DesignatedCity ;
ic:表記 ?city ;
sacs:prefectureLabel ?pref .
} ORDER BY DESC(?year) DESC(?observation)
PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?city ?year ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod ?year ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
{ ?areacode sacs:administrativeClass sacs:DesignatedCity .} UNION
{ ?areacode sacs:administrativeClass sacs:CoreCity .} UNION
{ ?areacode sacs:administrativeClass sacs:City .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialCity .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialWard .} UNION
{ ?areacode sacs:administrativeClass sacs:Town .} UNION
{ ?areacode sacs:administrativeClass sacs:Village .}
?areacode ic:表記 ?city ;
sacs:prefectureLabel ?pref .
} ORDER BY DESC(?year) DESC(?observation)
また、統計調査というものの性質上致し方ないことであるが、統計の種類により調査年が異なるのも利活用を難しくする一つの要因だ。最新年の情報のみ欲しい場合でも、一旦、すべての調査年の値を入手し、必要な年の値のみ抽出する必要がある。
最大のネックは、クエリが長くて処理が重すぎること。特に、全市区町村分を取得するクエリは、下手すると何分も待たされ、途中で寝てしまう。サーバに負荷をかけすぎて、他の利用者に迷惑をかけることにもなってしまう。
そこで、考えたのが以下のクエリ。(これは都道府県バージョン)
PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sac:<http://data.e-stat.go.jp/lod/sac/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
select ?year
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
sdmx-dimension:refArea sac:C01000-19700401 ;
cd-dimension:timePeriod ?year .
} ORDER BY DESC(?year)
PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod "(一段目で取得した調査年をセット)"^^xsd:gYear ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
?areacode sacs:administrativeClass sacs:Prefecture ;
ic:表記 ?pref .
} ORDER BY DESC(?observation)
上記のようにすると、二段階になり、一見遅くなるように思うが、全ての調査年を走査する必要がなくなるため、負荷が軽減され、結果として高速化される。しかしながら、これでもまだ重く、特に「全市区町村分」は途中で固まることもあり実用的ではない。
どの部分がボトルネックとなっているか調べた結果、『標準自治体コードをもとに、自治体名(市区町村、都道府県)を取得する部分』がかなり重いことが分かった。データセットを跨ぐと重くなるのだろうか。
(都道府県)
?areacode ic:表記 ?pref .
(市区町村)
?areacode ic:表記 ?city ;
sacs:prefectureLabel ?pref .
上記の問題を解消するため、クエリをもう一段階分割し、三段構成とすることとした。
そのクエリは以下のとおり。(これは全市区町村バージョン)
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?areacode ?pref ?city
where {
?areacode a sacs:StandardAreaCode ;
ic:表記 ?city ;
sacs:prefectureLabel ?pref .
} ORDER BY ?areacode
ホームページを開くと、上記【一段目】のクエリを自動的にエンドポイントへ送信し、全ての自治体の標準自治体コードと、対応する市区町村名、その上位自治体である都道府県名を取得し、クライアントPCのメモリにオブジェクトとして格納しておく。
このクエリはやや重いが、取得したオブジェクトは、ページを閉じたり、別のページに遷移するまではメモリに保持されるため、一度の取得で何度も使いまわしが可能だ。
メモリへの格納後、次に「札幌市」の調査年を取得、最後に観測値を取得する。
PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sac:<http://data.e-stat.go.jp/lod/sac/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
select ?year
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
sdmx-dimension:refArea sac:C01100-19731201 ;
cd-dimension:timePeriod ?year .
} ORDER BY DESC(?year)
PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
select ?areacode ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod "(二段目で取得した調査年をセット)"^^xsd:gYear ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
{ ?areacode sacs:administrativeClass sacs:DesignatedCity .} UNION
{ ?areacode sacs:administrativeClass sacs:CoreCity .} UNION
{ ?areacode sacs:administrativeClass sacs:City .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialCity .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialWard .} UNION
{ ?areacode sacs:administrativeClass sacs:Town .} UNION
{ ?areacode sacs:administrativeClass sacs:Village .}
} ORDER BY DESC(?observation)
上記クエリの結果がコールバックされたら、三段目で取得した「?areacode」と、一段目で取得済みの、メモリに格納してある標準自治体コード等の情報を Javascript でマッチングさせ、ブラウザ上に表示させる。
ブラウザ内でのマッチング作業に少し時間がかかるが、SPARQLサーバー上で行うよりもずっと高速だ。
Fusekiサーバー内でどのような処理が行われているか詳しいことは分からないが、重いクエリ一発で処理を行うより、軽いクエリを複数回組み合わせたほうが、結果として素早く処理が完了できるようだ。統計LODを利用したアプリケーション開発を考えておられる方には、このように細かくクエリを分割する手法をお勧めしたい。
余談だが、今回の統計LODリニューアル後のデータは、共通語彙基盤の語彙が多く使われており、その使いどころも、IPAの解説に近い形に手直しをされた。これは素晴らしい取組だと思う。その一方で、使われている共通語彙の名前空間URIが未だに「旧」であるところがイケてない(こちら参照)。速やかに新URIに修正していただきたいところだ。
統計LOD の SPARQL Endpoint はこちら。クエリをコピペして一度お試しあれ。
なお、アプリ上では、統計指標(述語 g00200502-dimension:indicator に対する 目的語)については、ドロップダウンリストで選択したものをセットするが、ここでは便宜的に「g00200502-code:indicator-A1101」(人口総数)にしている。
【都道府県】
PREFIX g00200502-dimension:<http://data.e-stat.go.jp/lod/ontology/g00200502/dimension/>PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?year ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod ?year ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
?areacode sacs:administrativeClass sacs:Prefecture ;
ic:表記 ?pref .
} ORDER BY DESC(?year) DESC(?observation)
【政令指定都市】
PREFIX g00200502-dimension:<http://data.e-stat.go.jp/lod/ontology/g00200502/dimension/>PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?city ?year ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod ?year ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
?areacode sacs:administrativeClass sacs:DesignatedCity ;
ic:表記 ?city ;
sacs:prefectureLabel ?pref .
} ORDER BY DESC(?year) DESC(?observation)
【全ての市町村及び東京特別区】
PREFIX g00200502-dimension:<http://data.e-stat.go.jp/lod/ontology/g00200502/dimension/>PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?city ?year ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod ?year ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
{ ?areacode sacs:administrativeClass sacs:DesignatedCity .} UNION
{ ?areacode sacs:administrativeClass sacs:CoreCity .} UNION
{ ?areacode sacs:administrativeClass sacs:City .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialCity .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialWard .} UNION
{ ?areacode sacs:administrativeClass sacs:Town .} UNION
{ ?areacode sacs:administrativeClass sacs:Village .}
?areacode ic:表記 ?city ;
sacs:prefectureLabel ?pref .
} ORDER BY DESC(?year) DESC(?observation)
全市区町村分を取得するクエリは、複数の自治体種別をUNIONで繋げているのがスマートでないが、これは統計LODの自治体情報のオントロジー構造の問題によるものであり、現状ではこうする他に手がない。次の「おまけコラム」で、その問題点について詳しく述べたので、改善していただけるとありがたい。
また、統計調査というものの性質上致し方ないことであるが、統計の種類により調査年が異なるのも利活用を難しくする一つの要因だ。最新年の情報のみ欲しい場合でも、一旦、すべての調査年の値を入手し、必要な年の値のみ抽出する必要がある。
最大のネックは、クエリが長くて処理が重すぎること。特に、全市区町村分を取得するクエリは、下手すると何分も待たされ、途中で寝てしまう。サーバに負荷をかけすぎて、他の利用者に迷惑をかけることにもなってしまう。
そこで、考えたのが以下のクエリ。(これは都道府県バージョン)
【一段目】都道府県のうち、北海道の調査年を取得
PREFIX g00200502-dimension:<http://data.e-stat.go.jp/lod/ontology/g00200502/dimension/>PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sac:<http://data.e-stat.go.jp/lod/sac/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
select ?year
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
sdmx-dimension:refArea sac:C01000-19700401 ;
cd-dimension:timePeriod ?year .
} ORDER BY DESC(?year)
【二段目】都道府県の名称と統計調査の観測値を取得
PREFIX g00200502-dimension:<http://data.e-stat.go.jp/lod/ontology/g00200502/dimension/>PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?pref ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod "(一段目で取得した調査年をセット)"^^xsd:gYear ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
?areacode sacs:administrativeClass sacs:Prefecture ;
ic:表記 ?pref .
} ORDER BY DESC(?observation)
上記のようにすると、二段階になり、一見遅くなるように思うが、全ての調査年を走査する必要がなくなるため、負荷が軽減され、結果として高速化される。しかしながら、これでもまだ重く、特に「全市区町村分」は途中で固まることもあり実用的ではない。
どの部分がボトルネックとなっているか調べた結果、『標準自治体コードをもとに、自治体名(市区町村、都道府県)を取得する部分』がかなり重いことが分かった。データセットを跨ぐと重くなるのだろうか。
(都道府県)
?areacode ic:表記 ?pref .
(市区町村)
?areacode ic:表記 ?city ;
sacs:prefectureLabel ?pref .
上記の問題を解消するため、クエリをもう一段階分割し、三段構成とすることとした。
そのクエリは以下のとおり。(これは全市区町村バージョン)
【一段目】全自治体の標準自治体コードと、市区町村名称及び都道府県名称を取得
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>PREFIX ic:<http://imi.go.jp/ns/core/rdf#>
select ?areacode ?pref ?city
where {
?areacode a sacs:StandardAreaCode ;
ic:表記 ?city ;
sacs:prefectureLabel ?pref .
} ORDER BY ?areacode
ホームページを開くと、上記【一段目】のクエリを自動的にエンドポイントへ送信し、全ての自治体の標準自治体コードと、対応する市区町村名、その上位自治体である都道府県名を取得し、クライアントPCのメモリにオブジェクトとして格納しておく。
このクエリはやや重いが、取得したオブジェクトは、ページを閉じたり、別のページに遷移するまではメモリに保持されるため、一度の取得で何度も使いまわしが可能だ。
メモリへの格納後、次に「札幌市」の調査年を取得、最後に観測値を取得する。
【二段目】市区町村のうち、札幌市の調査年の取得
PREFIX g00200502-dimension:<http://data.e-stat.go.jp/lod/ontology/g00200502/dimension/>PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sac:<http://data.e-stat.go.jp/lod/sac/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
select ?year
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
sdmx-dimension:refArea sac:C01100-19731201 ;
cd-dimension:timePeriod ?year .
} ORDER BY DESC(?year)
【三段目】全市区町村の統計調査の観測値を取得
PREFIX g00200502-dimension:<http://data.e-stat.go.jp/lod/ontology/g00200502/dimension/>PREFIX g00200502-code:<http://data.e-stat.go.jp/lod/ontology/g00200502/code/>
PREFIX cd-dimension:<http://data.e-stat.go.jp/lod/ontology/crossDomain/dimension/>
PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
PREFIX sdmx-measure:<http://purl.org/linked-data/sdmx/2009/measure#>
PREFIX sdmx-dimension:<http://purl.org/linked-data/sdmx/2009/dimension#>
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
select ?areacode ?observation
where {
?s g00200502-dimension:indicator g00200502-code:indicator-A1101 ;
cd-dimension:timePeriod "(二段目で取得した調査年をセット)"^^xsd:gYear ;
sdmx-measure:obsValue ?observation ;
sdmx-dimension:refArea ?areacode .
{ ?areacode sacs:administrativeClass sacs:DesignatedCity .} UNION
{ ?areacode sacs:administrativeClass sacs:CoreCity .} UNION
{ ?areacode sacs:administrativeClass sacs:City .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialCity .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialWard .} UNION
{ ?areacode sacs:administrativeClass sacs:Town .} UNION
{ ?areacode sacs:administrativeClass sacs:Village .}
} ORDER BY DESC(?observation)
上記クエリの結果がコールバックされたら、三段目で取得した「?areacode」と、一段目で取得済みの、メモリに格納してある標準自治体コード等の情報を Javascript でマッチングさせ、ブラウザ上に表示させる。
ブラウザ内でのマッチング作業に少し時間がかかるが、SPARQLサーバー上で行うよりもずっと高速だ。
Fusekiサーバー内でどのような処理が行われているか詳しいことは分からないが、重いクエリ一発で処理を行うより、軽いクエリを複数回組み合わせたほうが、結果として素早く処理が完了できるようだ。統計LODを利用したアプリケーション開発を考えておられる方には、このように細かくクエリを分割する手法をお勧めしたい。
余談だが、今回の統計LODリニューアル後のデータは、共通語彙基盤の語彙が多く使われており、その使いどころも、IPAの解説に近い形に手直しをされた。これは素晴らしい取組だと思う。その一方で、使われている共通語彙の名前空間URIが未だに「旧」であるところがイケてない(こちら参照)。速やかに新URIに修正していただきたいところだ。
統計LODの地方自治体オントロジーについての考察 (2017.12.28)
統計LODにおける地方自治体定義のオントロジーは、下図のような構成になっている。
このWEBアプリの「全市区町村」検索で必要な情報は、背景が黄色の部分だ。
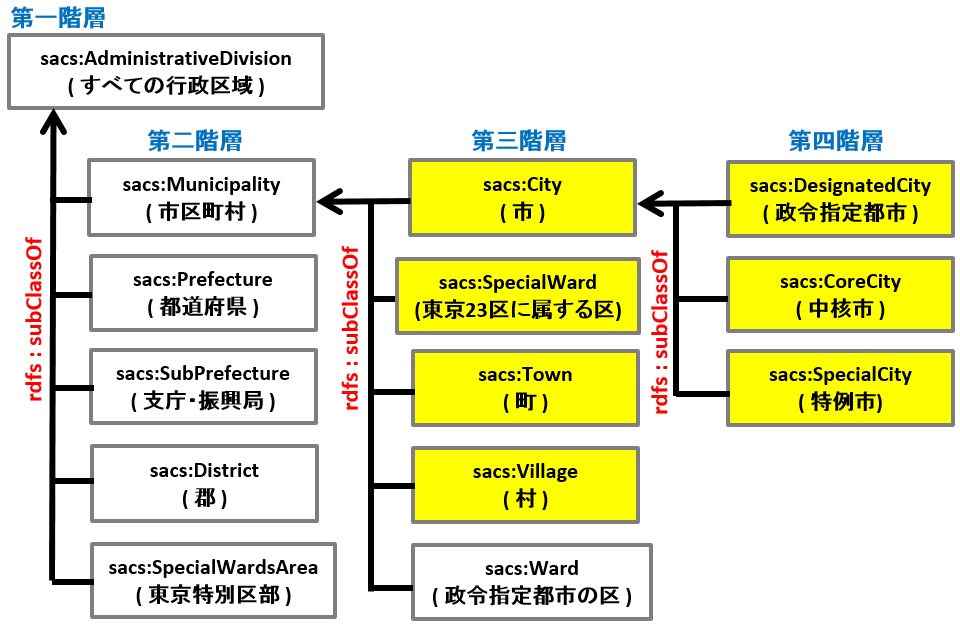
上図の「第三階層」は、市区町村クラスに属するグループであるが、市・東京23区・町・村に加え、「政令指定都市の行政区」も同格に扱うこととされている。
一般的に「市区町村」と言った場合、そこに政令指定都市の行政区を含めるかどうかは議論の分かれるところであるが、行政区は東京特別区とは異なり地方公共団体そのものではないので、クラス分類基準の同一性という観点で捉えると「含めない」のが正解だろう。
また、政令指定都市が属する第四階層より、行政区が属する階層のほうが浅い位置にあるのも違和感を覚える。
第三階層の「市」と、第四階層の「政令指定都市」「中核市」「特例市」との関係も、私の感覚では、不適当と感じられる。
現行の統計LODにおける、「市」のクラスとインスタンスの関係を図に表すと、以下の通りとなる。
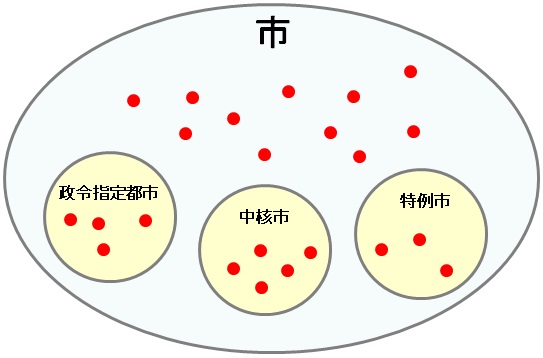
普通の市と、政令市・中核市・特例市が異なるクラス階層に属しているのは、オントロジー構成的にみても望ましくない上、実際にSPARQL検索を行う際にも不便だ。
現行では、政令市等を含めたすべての「市」を取得したい場合、以下のように UNION で繋げる必要があり、これではスマートでない。
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
select ?areacode
where {
{ ?areacode sacs:administrativeClass sacs:City .} UNION
{ ?areacode sacs:administrativeClass sacs:DesignatedCity .} UNION
{ ?areacode sacs:administrativeClass sacs:CoreCity .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialCity .}
}
または
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?areacode
where {
{ ?bigCity rdfs:subClassOf sacs:City .
?areacode sacs:administrativeClass ?bigCity . } UNION
{ ?areacode sacs:administrativeClass sacs:City .}
}
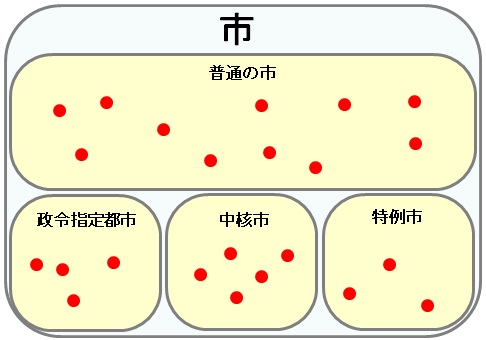
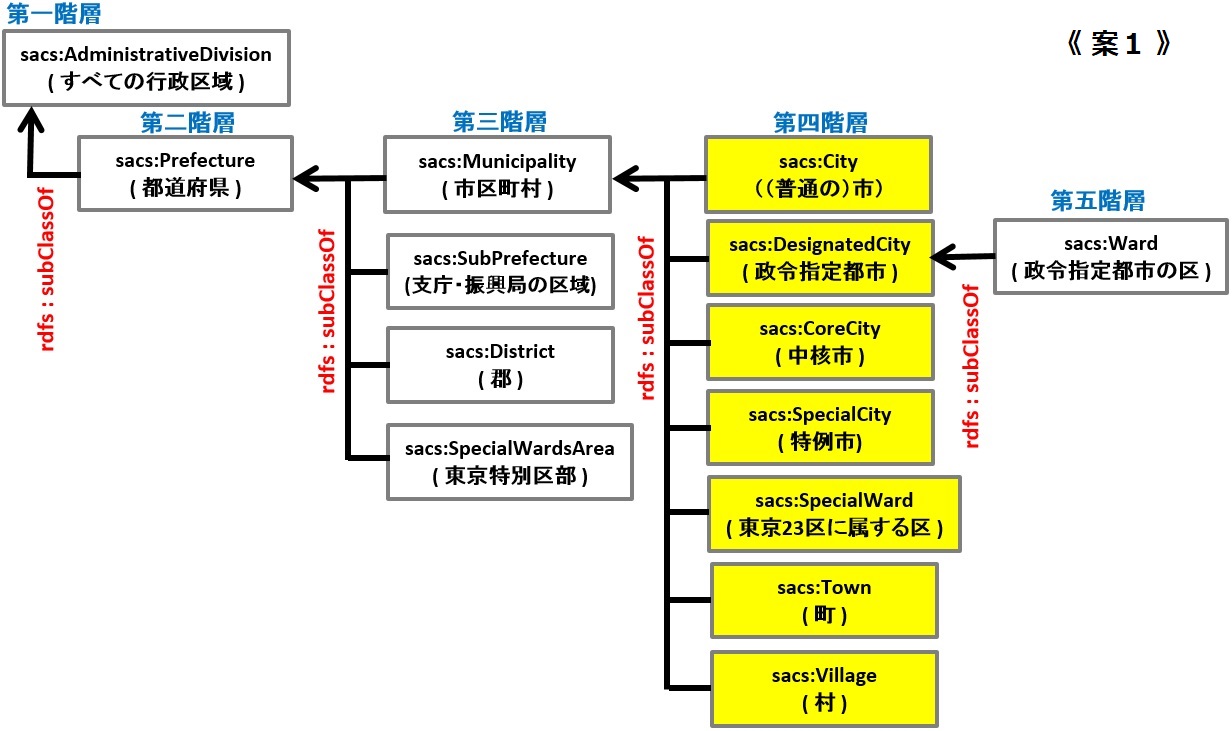
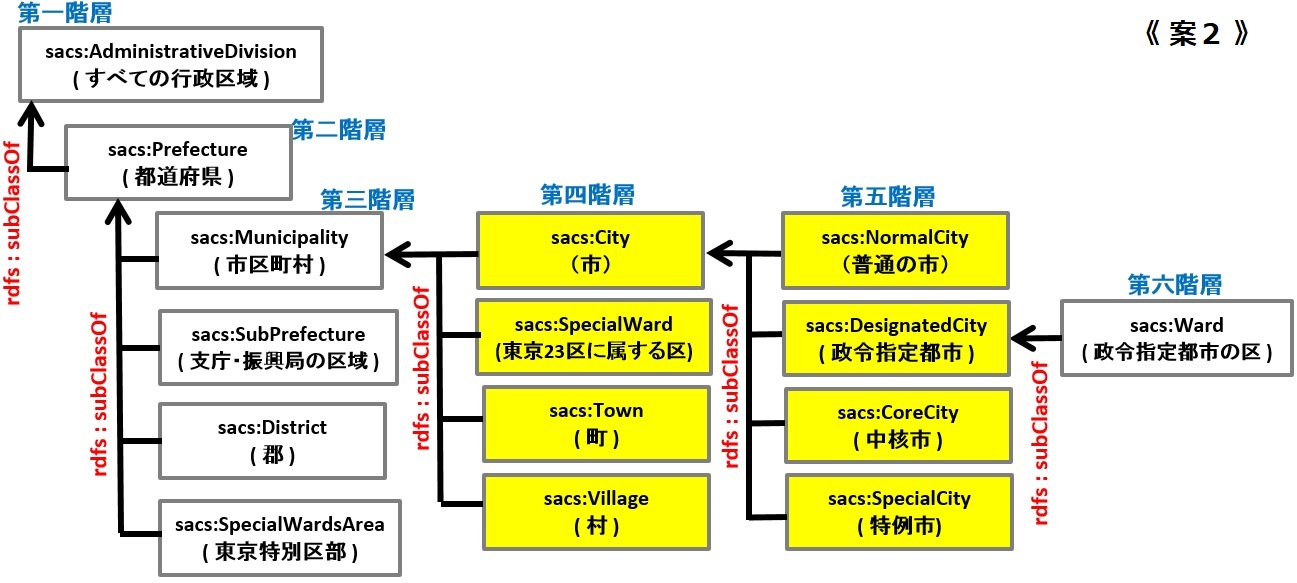
私としては、下図のような構成が望ましいと考える。この構成であれば、インスタンス集合のパーティション性を満たし、かつ、スマートで高速なクエリが使えるため、利便性も高い。
SPARQLサーバーのレスポンスを向上させるには、機器の物理的な増強だけでなく、このようなオントロジーの見直しからもアプローチすべきだろう。
(クエリ)
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?areacode
where {
?allCity rdfs:subClassOf sacs:City .
?areacode sacs:administrativeClass ?allCity .
}
私は、統計LODの地方自治体オントロジーについて、オントロジーとして望ましい状態に修正し、同時にSPARQL検索の利便性も向上させるため、下図《 案1 》又は《 案2 》が良いと考えている。統計局及び統計センターの関係者の方、ご検討願います。
粗探しのような要望ばかり述べてしまったが、今回のリニューアルにより、データセットが拡充され、使い勝手もずいぶん良くなったことは間違いなく、私のようなマニアには嬉しい限りだ。
統計LODのさらなる発展と、地方自治体の統計データLOD化の波及を願い、微力ながら私も応援していきたい。
このWEBアプリの「全市区町村」検索で必要な情報は、背景が黄色の部分だ。
上図の「第三階層」は、市区町村クラスに属するグループであるが、市・東京23区・町・村に加え、「政令指定都市の行政区」も同格に扱うこととされている。
一般的に「市区町村」と言った場合、そこに政令指定都市の行政区を含めるかどうかは議論の分かれるところであるが、行政区は東京特別区とは異なり地方公共団体そのものではないので、クラス分類基準の同一性という観点で捉えると「含めない」のが正解だろう。
また、政令指定都市が属する第四階層より、行政区が属する階層のほうが浅い位置にあるのも違和感を覚える。
第三階層の「市」と、第四階層の「政令指定都市」「中核市」「特例市」との関係も、私の感覚では、不適当と感じられる。
現行の統計LODにおける、「市」のクラスとインスタンスの関係を図に表すと、以下の通りとなる。
普通の市と、政令市・中核市・特例市が異なるクラス階層に属しているのは、オントロジー構成的にみても望ましくない上、実際にSPARQL検索を行う際にも不便だ。
現行では、政令市等を含めたすべての「市」を取得したい場合、以下のように UNION で繋げる必要があり、これではスマートでない。
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
select ?areacode
where {
{ ?areacode sacs:administrativeClass sacs:City .} UNION
{ ?areacode sacs:administrativeClass sacs:DesignatedCity .} UNION
{ ?areacode sacs:administrativeClass sacs:CoreCity .} UNION
{ ?areacode sacs:administrativeClass sacs:SpecialCity .}
}
または
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?areacode
where {
{ ?bigCity rdfs:subClassOf sacs:City .
?areacode sacs:administrativeClass ?bigCity . } UNION
{ ?areacode sacs:administrativeClass sacs:City .}
}
私としては、下図のような構成が望ましいと考える。この構成であれば、インスタンス集合のパーティション性を満たし、かつ、スマートで高速なクエリが使えるため、利便性も高い。
SPARQLサーバーのレスポンスを向上させるには、機器の物理的な増強だけでなく、このようなオントロジーの見直しからもアプローチすべきだろう。
(クエリ)
PREFIX sacs:<http://data.e-stat.go.jp/lod/terms/sacs#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select ?areacode
where {
?allCity rdfs:subClassOf sacs:City .
?areacode sacs:administrativeClass ?allCity .
}
私は、統計LODの地方自治体オントロジーについて、オントロジーとして望ましい状態に修正し、同時にSPARQL検索の利便性も向上させるため、下図《 案1 》又は《 案2 》が良いと考えている。統計局及び統計センターの関係者の方、ご検討願います。
粗探しのような要望ばかり述べてしまったが、今回のリニューアルにより、データセットが拡充され、使い勝手もずいぶん良くなったことは間違いなく、私のようなマニアには嬉しい限りだ。
統計LODのさらなる発展と、地方自治体の統計データLOD化の波及を願い、微力ながら私も応援していきたい。
登録:
投稿 (Atom)